(本站固定节目)
那四个转接器组的垃圾已经难以满足博主日益增长的高速稳定大容量存储需求。目前这4块盘已经掉了一块不认一块,估计随时有暴毙的风险。

TrueNAS 提示磁盘未分配,意味着有该盘的阵列无法启动
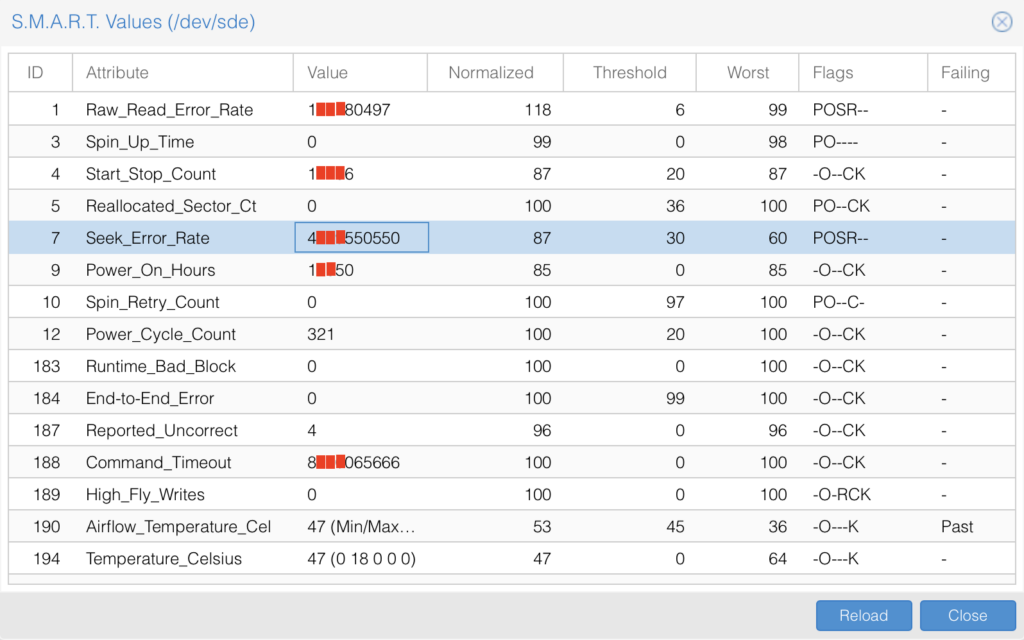
没有05但仍然震撼人心的SMART信息(破案了,希捷就是这么混乱的SMART)
经过长时间的运行测试,该阵列在大量读写时有极大概率卡死 IO 或有磁盘连接波动,并数次出现连接无法恢复。更糟糕的是,由于硬盘通过 QEMU 虚拟化方式挂载,掉盘会导致 TrueNAS 离线,使得依赖其 NFS 共享的 Nextcloud 服务器一起爆炸。要修复该问题,只能删除离线的磁盘后再启动,直到通过玄学插拔修复磁盘连接。
顺带一提,USB2.0 转出4块硬盘组阵列的性能确实不理想。这不仅仅是USB2.0的速率上限所导致,还有 USB2.0 的半双工 IO 开销更大、接口松动误码率更高、USB Host 不堪重负之类的因素。
上述补丁能在各硬盘数据正常的前提下容忍1块盘断线/故障,但目前已经超过临界值了,必须出重拳(早干什么去了)。结合散热系统和PVE跨版本升级维护需要,综合考虑本周“形势与政策”课程安排,博主特别发起自本周五下午开始的“整治掉盘卡死专项行动”,内容包括:
- PC 通过 SATA 直连取下的硬盘,分别检查四个硬盘的健康状况,特别是分区表是否还健在
- 改为使用成品金属支架固定硬盘
- 将硬盘 5V 供电从USB接口取电,升级为通过 XL4016E1 降压模块输出。该5V由12V供电转出,模块最大输出电流8A
- 拆机清灰换硅脂
- 将四个 USB2.0 – SATA 转接器升级为 Marvell 9215 主控的 miniPCIe 转接器,从额外的机身开孔穿过,使用 SFF8087 – SATA 线缆与硬盘连接
- 给硬盘阵列安装风扇
- 备份虚拟机,并拷贝快照到主机外的存储器
- 升级PVE9,支持直接运行 Docker 容器
- 将 peerBanHelper 等 Docker 容器从 TrueNAS 转移到 PVE 中运行,减小重复虚拟化性能开销(为啥 PBH 用 Java 啊)
如果我还有精力的话,应该会写一篇博客记录这个